토픽 이름 | 빅데이터 분석 기법(알고리즘) |
분류 | 데이터베이스 > Big Data > 빅데이터 분석 기법(알고리즘) |
키워드(암기) | (리드문) 분류모델 생성 알고리즘 |
Bagging, Boosting, Train-Validation, Cross-Validation, K-fold Cross-Validation, Bootstrap | |
암기법 (해당경우) |
|
기출문제
번호 | 문제 | 회차 |
1 | 빅데이터 분석기법인 Random Forest에 대해 설명하시오. | 110_관리_1교시 |
2 | 12. Bagging과 Boosting을 설명하시오 | 모의(18.07)_응용_1교시 |
I. 분류모델 생성 알고리즘 Bagging과 Boosting
Bagging | Boosting |
- 주어진 데이터에서 여러 개의 bootstrap 자료를 생성하고, 각 자료를 모델링 한 후 결합(Bootstrap Aggregating)하여 최종 예측 모형을 만드는 알고리즘 | - 잘못 분류된 개체들에 가중치를 적용하여 새로운 분류규칙을 만들고, 이 과정을 반복해 최종 예측 모형을 만드는 Boosting(변형) 알고리즘 |
- Bagging과 Boosting은 데이터 마이닝에서 분류를 수행하기 위한 분류모델을 생성하는 알고리즘
II. Bagging과 Boosting 알고리즘 비교 설명
가. Bagging과 Boosting 알고리즘 수행방법 비교
구분 | 설명 |
Bagging |
|
1) Row data에서 bootstrap 데이터 추출 2) 추출을 반복하여 n개의 데이터 생성 3) 각 데이터를 각각 모델링 하여 모델 생성 4) 단일 모델을 결합하여 배깅 모델 생성 | |
Boosting |
|
1) Row data에 동일가중치로 모델 생성 2) 생성된 모델로 인한 오분류 데이터 수집 3) 오분류 데이터에 높은 가중치 부어 4) 과정 반복을 통하여 모델의 정확도 향상 |
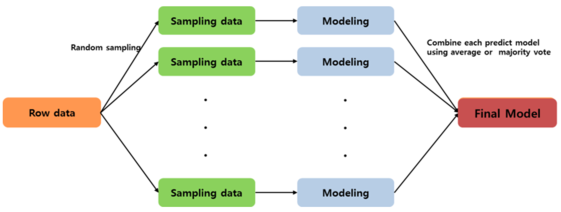
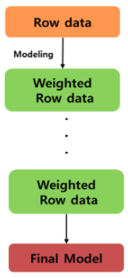
- Bagging은 여러 번의 sampling을 통해 분산을 줄여 모델의 변동성을 감소시키는 방법
- Boosting은 잘못 분류된 데이터에 집중해 모델의 정확도를 향상시키는 방법
나. Bagging과 Boosting 알고리즘의 기술적 특징 비교
항목 | Bagging | Boosting |
수행원리 | - 샘플링에 의한 결합 | - 가중치 재조정에 의한 반복 |
수행목적 | - 모델의 변동성(분산)을 감소 | - 모델의 정확도 향상 |
적용연산 | - 평균, 다중투표 | - 가중치 선형 결합 |
초기모델 | - Bootstrap 모델 (개별 모델) | - Weak classification 모델 |
최종모델 | - Bagging 모델 (결합 모델) | - Strong classification 모델 |
분류성능 | - 데이터에 결측치(missing data)가 존재할 경우 우수 | - 데이터의 수가 많을 경우 우수 |
- 데이터 마이닝에서 분류문제를 해결하고자 할 때 중요한 문제는 주어진 데이터를 이용해 목표변수를 가장 잘 예측할 수 있는 모델을 생성하는 것이므로, 데이터 특성에 따라 모델을 생성하는 알고리즘의 선택적 적용이 필요함
III. 빅데이터 모델 평가 방법
나. Train-Validation
- 데이터 마이닝을 통해 생성된 모델의 에러율 예측을 통해 모델의 타당성을 평가하는 검증 방법으로
훈련집합, 확인(검증)집합, 테스트 집합으로 모델 정확도 검증 방법

데이터 Set | 설명 | 활용 |
Training Set |
| 모델 학습 |
Validation Set |
| 모델 선택 |
Test Set | 최종 선택 모형이 새로운 데이터에 대하여 좋은 성과를 갖는지 평가 (테스트집합) | 모델 평가 |
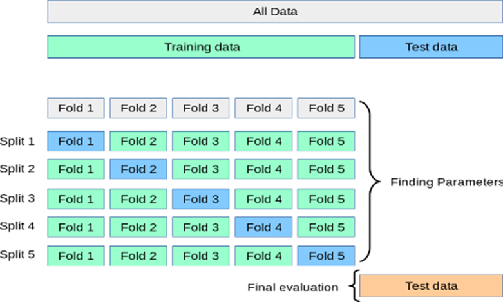
다. 교차검증(Cross-validation)
- 데이터 Training Data를 몇 개의 폴드로 구분하여, 그 안에서, Training Data, Test Data로 사용하고 마지막에 사용하지 않은 data로 Test Data를 사용하는 방법

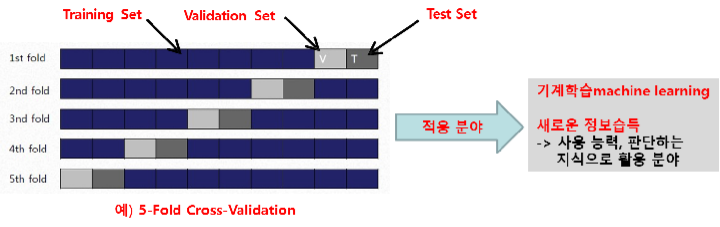
라. K-fold Cross-Validation
- Training Set을 K로 등분하여, Rounding 하는 기법(Training Set을 k개의 부분 집합으로 등분하고, 각각 검증한
결과의 평균으로 모델을 검증함
- k-1개로 학습하고, 나머지 한 개로 테스트. 이런 과정을 서로 다른 부분 집합으로 k번 수행하여 얻은 성능을
평균함(3개 데이터 집합 모두 사용됨; 데이터 부족한 경우 장점)
- 이를 k-fold Cross Validation이라 함
- k=N인 경우(N은 샘플 개수) 하나 남기기(Leave-one-out) 또는 잭나이프(Jackknife) 기법이라 함
- 원시 Data Set 에서 Training Set, Validation Set, Test Set에 속한 Datum(원소)을 K회 바꿔서 성능을 검증하는
방법 (Random추출, 구간 추출)
★★ 그림 설명: V, T 항목을 각각 구간별 바꾸면서, 모델 성능 검증/Holdout 단어가 없음
'보관함' 카테고리의 다른 글
| 데이터 리터러시 (0) | 2020.01.22 |
|---|---|
| 상호 배제(Lock, Unlock) 기능을 사용하는 동시성 제어 기법, Locking 기법 개요 (0) | 2020.01.22 |
| 분류모델 생성 알고리즘 Bagging과 Boosting (0) | 2020.01.22 |
| 빅데이터 분석기법, Random Forest의 개요 (0) | 2020.01.21 |
| 과잉 학습으로 인한 폐해, 과적합(Overfitting)의 개요 (0) | 2020.01.21 |