토픽 이름 | 랜덤 포리스트(Random Forest) |
분류 | 데이터베이스 > Big Data > 랜덤 포리스트(Random Forest) |
키워드(암기) | (리드문) 빅데이터 분석기법 |
임의 최적노드, 배깅, 결정 트리, 정규화 랜덤 포레스트, 앙상블, Bagging | |
암기법 (해당경우) |
|
기출문제
번호 | 문제 | 회차 |
1 | 빅데이터 분석기법인 Random Forest에 대해 설명하시오. | 110.관리.1 |
2 | 10. 랜덤 포레스트(Random Forest)에 대해 설명하시오. | 합숙_2018.01_공통_Day1 |
I. 빅데이터 분석기법, Random Forest의 개요
가. Random Forest 정의
- 여러 개의 결정 트리들을 임의적으로 학습하는 방식의 앙상블 방법으로서, 배깅(bagging)보다 더 많은 임의성을 주어 학습기들을 생성한 후 이를 선형 결합하여 최종 학습기를 만드는 방법
- 다수의 결정 트리를 구성하는 학습 단계와 입력 벡터가 들어왔을 때 분류하거나 예측하는 테스트 단계로 구성 되어있는 기계학습방법
나. Random Forest 사용 기법
기법 | 내용 |
앙상블 학습 | - 주어진 데이터로부터 여러 개의 모델을 학습한 다음, 예측 시 여러 모델의 예측 결과들을 종합하여 정확도를 높이는 기법으로써, 여러 개의 의사결정트리를 만들고 투표하여 다수결로 결과를 결정하는 방법 |
배깅(Bagging) | - 주어진 데이터에 대해 여러 개의 부트스트랩(bootstrap) 데이터를 생성하고 각 예측모형을 만든 후 결합하여 최종 예측모형을 만드는 방법 |
다. Random Forest의 부각배경
배경 | 내용 |
의사결정트리의 한계존재 | - 결과 또는 성능의 변동폭이 크다는 문제 및 학습데이터에 따라 생성되는 결정트리가 크게 달라져 일반화하기 어려운 과적합(overfitting)문제 - 계층적 접근방식으로서 중간에 에러발생 시 다음단계로 에러가 전파 |
과적합 문제 극복필요 | - 임의화 기술을 통해 각 일반화 성능을 향상시켜 과적합문제 극복의 필요 |
-
라. Random Forest의 특징
1) 임의성(randomness)에 의해 서로 조금씩 다른 특성을 갖는 트리들로 구성
2) 각 트리들의 예측(Prediction)들에 대한 비상관화(decorrelation)
3) 일반화 성능의 향상 및 노이즈(noise)에 강함
4) 임의화를 통한 과적합(overfitting)문제를 극복
II. Random Forest의 주요기법
가. 배깅(bagging)을 이용한 forest 구성
- 부트스트랩(bootstrap)을 통해 조금씩 다른 훈련 데이터에 대해 훈련된 기초 분류기(base learner)들을 결합(aggregating)시키는 방법
단계 | 내용 |
데이터집합생성 | - 부트스트랩(bootstrap)을 통해 T개의 훈련데이터 집합 생성 |
훈련 | - T개의 기초분류기(tree)들을 훈련시킨다 |
결합 | - 기초분류기(tree)들을 하나의 분류기(random forest)로 결합(평균 또는 과반수투표 방식 이용) |
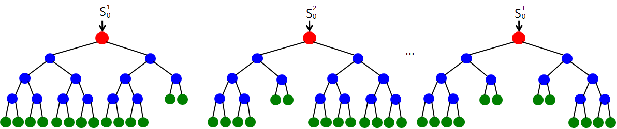
- 배깅(bagging)을 이용해 T개의 결정 트리들로 구성된 Random Forest를 학습하는 과정
나. 임의노드 최적화(randomized node optimization)
- 분석에 사용되는 변수를 랜덤하게 추출하는 것으로써, 훈련단계에서 훈련목적함수를 최대로 만드는 노드분할 함수의 매개변수 θ의 최적값을 구하는 과정
구성요소 | 내용 |
노드분할 함수 | - 각 트리의 노드마다 좌측, 우측 자식노드로 분할하기 위해 가지는 함수
- 0은 거짓(false), 1은 참(true) - 분할 함수는 매개변수에 따라 결정 |
훈련목적 함수 | - 매개변수의 최적값는 임계값들안에서, 정보 획득량(information gain)을 최대로 만들게 하는 값을 계산 |
임의성 정도 | - 비상관화 수준의 결정요소로서 로 결정 - 로 고정시켜두고 random forest를 훈련시킬 경우, 매개변수 를 대입하여 임의성 정도를 설명할 수 있으며, 에서 임의성의 정도를 결정 - 보통 의 값은 random forest 트리들의 모든 노드에서 동일한 값 사용 - 이면 모든 트리들이 동일하게 되어 임의성이 주입되지 않으며, 인 경우 최대의 임의성과 비상관화(uncorrelated)된 트리를 얻게 됨 |
- 즉, 분석을 위해 준비된 데이터로부터 임의복원추출을 통해 여러 개의 학습데이터를 추출하고 각각 개별학습을 시켜 트리를 생성하여 투표 또는 확률 등을 이용하여 최종목표변수를 예측
다. 중요 매개변수
구성요소 | 내용 |
forest의 크기 | - 총 forest를 몇 개의 트리로 구성할 지를 결정하는 매개변수 - forest가 작으면 트리들의 구성 및 테스트 시간이 짧은 대신, 일반화 능력이 떨어지는 반면, forest의 크기가 크다면 훈련과 테스트 시간은 증가하지만 forest의 결과값의 정확성/일반화 능력이 우수 |
최대 허용 깊이 | - 하나의 트리에서 루트 노드부터 종단 노드까지 최대 몇 개의 노드(테스트)를 거칠 것인지를 결정하는 매개변수 - 최대 허용 깊이가 작으면 과소적합(underfitting) 발생, 최대 허용 깊이가 크면 과대적합(overfitting)이 일어나기 때문에 적절한 값 설정필요 |
임의성 정도 | - 임의성의 정도에 따라 비상관화 수준의 결정 |
III. Random Forest의 응용사례
사례 | 내용 |
키넥트에서의 신체 트랙킹 | - 엑스박스 360에서 사용되는 모션 캡처 주변기기인 키넥트에서는 random forest를 이용하여 주어진 입력에서 신체의 각 부분을 분류 |
컴퓨터 단층촬영에서의 해부학 구조 분석 | - 3차원 컴퓨터 단층촬영 영상(Computed Tomography, CT) 내에서 주어진 복셀에 대해 해당되는 해부학구조가 어디인지 검출하고 해당 위치를 파악 |
다채널 자기공명영상 분석 | - 브라운대학, 캠브리지대학 등에서 다채널 자기공명영상(Multi-channel Magnetic resonance image)으로 촬영된 뇌 영상에서 고악성도 신경교종(High-grade gliomas)를 검출 |
'보관함' 카테고리의 다른 글
| 분류모델 생성 알고리즘 Bagging과 Boosting (0) | 2020.01.22 |
|---|---|
| 분류모델 생성 알고리즘 Bagging과 Boosting (0) | 2020.01.22 |
| 과잉 학습으로 인한 폐해, 과적합(Overfitting)의 개요 (0) | 2020.01.21 |
| 기업의 차세대 생존전략, 빅 데이터의 개요 (0) | 2020.01.21 |
| 빅데이터 시각화 (0) | 2020.01.21 |