|
토픽 이름 |
빅데이터 아키텍처/기술요소 |
|
분류 |
데이터베이스 > Big Data > 빅데이터 아키텍처/기술요소 |
|
키워드(암기) |
(리드문) 기업의 차세대 생존전략 |
|
데이터의 다양화 및 대용량화, 생성주체(컴퓨터, 사람, 관계) / 유형(정형/반정형/비정형) / 저장방식(3V / 기업 / 이산), 5V (Volume, Velocity, Variety, Value, Veracity) / NoSQL, 필연적 분석작업, DW연계, Big Data Appliance, Data Warehouse, 비즈니스 분석 도구, Front End, Middle Tier, Back End, System Mgmt, Text Mining, Opinion Mining, Social N/W Analytics, Cluster Analysis, Splunk(스플렁크), Flume(플럼), Chukwa(척와), Scribe(스크라이브), 로그수집기, 크롤링, 센싱, RSS, Open API |
|
|
암기법 (해당경우) |
|
기출문제
|
번호 |
문제 |
회차 |
|
1 |
기업경쟁력 제고를 위해 빅데이터(BigData) 분석의 중요성이 대두됨에 따라, 기업의 문제점을 체계적으로 파악하고, 이를 해결하여 사업적 가치를 재평가하기 위해서는 통합적 빅데이터 프로젝트 수행이 필요하다. 빅데이터 분석의 특징을 설명한 후 적절한 수행 절차와 각 단계에서의 처리내용을 설명하시오. |
113.관리.4 |
|
2 |
빅데이터 분석기법인 Random Forest에 대해 설명하시오. |
110.관리.1 |
|
3 |
빅데이터의 3V(Volume, Variety, Velocity) 특성과 빅데이터 활용에 따른 비즈니스 측면에서의 기대효과를 설명하시오. |
107.관리.3 |
|
4 |
빅데이터 분석방법인 Bagging과 Boosting 기법을 비교하여 설명하시오 |
105.관리.1 |
|
5 |
빅데이터 분산처리시스템인 하둡 MapReduce의 한계점을 중심으로 Apache Spark와 Apache Storm을 비교하여 설명하시오 |
105.관리.2 |
|
6 |
빅데이터 분석 도구인 R의 역사와 주요 기능 3가지에 대해 설명하시오. |
104.관리.4 |
|
7 |
Big Data 분석에서 모델 평가 방법인 Train-Validation, Cross-Validation , Bootstrap을 비교 설명하시오. |
102.관리.2 |
|
8 |
빅 데이터(Big Data)의 주요 요소 기술인 수집, 공유, 저장·관리, 처리, 분석 및 지식 시각화에 대하여 설명하시오. |
102.응용.4 |
|
9 |
빅데이터 핵심기술을 오픈소스와 클라우드 측면에서 설명하고, 표준화 기구들의 동향을 설명하시오. |
101.관리.2 |
|
10 |
2. 데이터의 폭증으로 대표되는 Big Data가 최근 다양한 분야에 활용되고, Big Data 처리 및 분석능력이 기업의 경쟁력으로 인식되고 있다. 다음에 대해 설명하시오. 가. Big Data 3대 요소(3V) 나. Big Data 분석 기법 다. Big Data 활용 분야 |
98.관리.3 |
|
11 |
빅데이터(Big Data) 분석과 기존 경영정보 분석과의 차이점에 대하여 설명하고, 빅데이터 분석의 활용효과에 대하여 설명하시오. |
96.관리.2 |
I. 기업의 차세대 생존전략, 빅 데이터의 개요
가. 빅 데이터(Big Data)의 정의
- 다양한 종류의 대규모 데이터로부터 저렴한 비용으로 가치를 추출하고, (데이터의) 초고속 수집, 발굴 분석을 지원하도록 고안된 차세대 기술 및 아키텍처
- 시스템, 서비스, 조직 등에서 주어진 비용, 시간 내에 처리 가능한 데이터 범위를 넘어서는 데이터
- 일반적인 데이터베이스 소프트웨어가 저장, 관리, 분석할 수 있는 범위를 초과하는 규모의 데이터
나. 빅 데이터의 등장배경

- 다양한 기기 사용에 따른 데이터의 다양화 및 대용량화
다. 빅 데이터의 3요소와 주요 특징
|
구분 |
내용 |
|
|
3V |
Volume |
- 대규모의 데이터량, 수십 페타/엑사/제타 바이트 수준의 대규모 Data |
|
Velocity |
- 데이터의 생성속도, 실시간에 가까운 빠른 속도 처리(Real Time) |
|
|
Variety |
- 데이터의 다양성, 정형/비정형의 다양한 Data |
|
|
5V |
Value |
- 빅 데이터로부터 추출되는 가치(Value)강조 - 분석결과의 가치 유무 판단 |
|
Veracity |
- 신뢰할 수 있는 정보를 얻을 수 있는 데이터들의 품질 - 도출된 정보의 신뢰성 |
|
|
특징 |
NoSQL |
- 개개의 data에 대한 ACID 특성 지원 불필요 |
|
분산처리, 확장성 |
- 대규모 Data, Hadoop 기반 처리(HDFS, Map Reduce) |
|
|
필연적 분석작업 |
- R을 이용한 통계처리, Data Mining 기반 패턴 분석을 통한 숨겨진 정보/지식 탐색 |
|
|
DW 연계 |
- DW로 저장하여 연관, 분류, 군집 분석 수행 |
|

II. 빅 데이터 아키텍처 구성도 및 기술 구성요소
가. 빅 데이터 아키텍처 구성도

- Big data 가용성 제고를 위해 데이터 처리 최적화된 기술 요소로 구성됨
나. 빅 데이터 기술 구성요소
|
구성요소 |
설명 |
사례 |
|
|
Front End |
경량script언어 |
- GC(graphics context) 성능 및 UI 구현 이용, 스크립트언어로 Front End 구성 |
Ruby on Rails, Scala, JavaScript, python, PHP |
|
경량App Server |
- 다수의 경량 Application Server를 이용하여 사용자 응답성의 극대화 |
Apache Thrift, Apache Avro, Jetty, Tomcat, NginX |
|
|
Front (Page) Cache |
- 정적 리소스 및 동적데이터에 대한 캐시서비스로 App/DB 서버부하절감 및 응답성 향상 |
Varnish cache, squid cache, Apache traffic server |
|
|
Middle Tier |
캐시Pool |
- DBMS를 통해 빈번하게 조회된 데이터를 메모리에 캐시하여 DB 부하 절감 및 응답속도 향상 |
Memcached, Membase(CouchBase), Ehcache, Oracle Coherence |
|
분산Middleware |
- 분산Application 서버와 Database간의 투명성과 Fault-tolerant를 제공하는 분산메시지기반 미들웨어 |
Kestrel(twitter), Apache ActiveMQ, ZeroMQ |
|
|
Back End |
분산파일시스템 |
- 분산Application 서버와 분산Database를 수평적으로 확장 가능케하는 네트워크기반의 분산파일 |
GFS(Google), Apache HDFS |
|
분산데이터 스토리지/ 연산처리 |
- 기본적으로 데이터의 분산관리를 지원하며 인덱스의 최적화에 집중화된 DB로 데이터 쓰기가 많은 업무의 실시간 데이터 처리에 최적화된 DB |
Hadoop, Map/Reduce, HBase, MongoDB, Cassandra |
|
|
DW&검색엔진 |
- 확장 가능한고 성능정보 검색서비스용 라이브러리엔진 및 DW 엔진 |
|
|
|
System Mgmt |
시스템관리/ 모니터링/ 분석도구 |
- 시스템로그, 성능, 응답성 등을 분석하고 표현하여 신속한 문제 파악과 주요 지표관리를 통해 운영조직의 대응(아키텍처Renewal) 여부와 시점에 대한 의사결정지원, 사용자의 서비스 불만 발생 전에proactive한 대응이 가능 |
Apache Zookeeper, Apache Chukwa, Scribe(FaceBook), Jconsole, Java Melody |
|
최적화도구 |
- CPU, 메모리 사용량에 대한Profiling과 분석을 지원하는S/W도구를 사용, 극한의 성능구현 |
yourkit |
|
III. 빅 데이터 분석 기법 및 기술 요소
가. 빅 데이터 분석 기법
|
분석 기법 |
설명 |
|
Text Mining |
- 자연어처리기술 기반 정보 추출, 가공 - Text Data에서 의미 있는 정보 추출 - 다른 정보와의 연계성 파악 - Text가 가진 카테고리 분류 - 문서 분류, 문서 군집, 문서 요약, 정보 추출 |
|
Opinion Mining |
- 평판분석 기법 - 소셜미디어 등의 긍정, 부정, 중립 선호도 판별 기술 - 특정 서비스 및 상품에 대한 시장규모 예측, 소비자 반응, 입소문 분석 등에 활용 - 정확성을 위해서는 전문가에 의한 선호도 표현/단어 자원의 축적이 필요함 |
|
Social N/W Analytics |
- Social N/W 연결구조, 연결강도를 바탕으로 사용자의 명성 및 영향력 측정 - Social N/W 상에서 입소문의 중심이나 Hub 역할을 하는 사용자를 찾는데 주로 활용 |
|
Cluster Analysis |
- 비슷한 특성을 가진 개체를 합쳐가면서 최종적으로 유사 특성의 Group 발굴 |
나. 빅 데이터 기술 요소
|
기술 요소 |
설명 |
|
Hadoop |
- Open Source 분산처리 기술 Project - 현재 정형/비정형 Big Data 분석에 가장 선호되는 솔루션 - Yahoo, Facebook 등
|
|
Map & Reduce |
- Map: 흩어져 있는 데이터를 key, value구조로 묶는 연산 - Reduce: Map작업 후, 중복데이터를 제거하고 데이터 추출
|
|
R |
- 통계 계산 및 시각화를 위한 언어 및 개발 환경 제공 - 구현 결과를 Graph 등으로 시각화 가능 - Java, C, Python 등 다른 프로그래밍 언어와 연결 용이 - Mac OS, 리눅스/유닉스, 윈도우 등 대부분의 컴퓨팅 환경 지원 - Hadoop 환경 상 분산처리를 지원하는 라이브러리 제공 - Google, Facebook, Amazon 등 |
|
NoSQL |
- Not only SQL, No SQL - 전통적인 관계형 DB와 다르게 설계된 비관계형 DB - Table Schema 고정되지 않고, Join 연산 지원 안 함 - 수평적 확장 용이 - CAP Theorem
|
- Big Data의 적극적 활용을 통한 서비스/상품 혁신을 위해서는 내/외부 Data 통합, 수집/분석역량, 인프라, 조직 분야에서의 체계적 준비 필요



IV. 빅 데이터 관리 방안
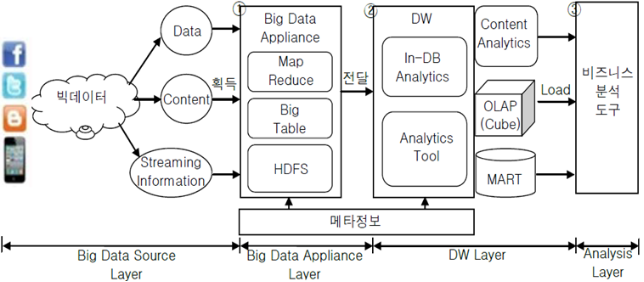
|
구분 |
주요 관리방안 |
적용기술 |
|
Big Data Appliance |
- 외부로부터 유입된 Big Data를 전문 Appliance에서 처리 - Big Data를 분산처리 방식에 의해 (Key-value) 형태로 처리 - 처리된 데이터는 Big Table에 저장 후 관리됨 |
- Map-Reduce - Big Table |
|
Data Warehouse |
- Big Table에 저장된 데이터 중 정형데이터를 추출하여 DW 적재 - 빠른 데이터 처리 및 데이터 컬럼 단위 압축 - 다차원 모델링에 의한 데이터 처리 수행 |
- HOLAP, ROLAP - Data Mining, ETL - Star스키마 - Snowflake스키마 |
|
비즈니스 분석 도구 |
- 고급 분석기술 및 데이터 사이언티스트를 통한 분석 실시 - 데이터의 가치에 따라 ILM과 연계하여 데이터 보관 및 관리 |
- Content Analysis - 예측분석 - Real time Analysis |
- 내용분석 기법 및 OLAP, MART 등을 통해 비즈니스 분석도구로 전달되어 의사결정을 위한 정보 분석 및 가치 기반 저장관리
V. 빅데이터 수집기술의 개념 및 도구, 자동수집 방법
가. 빅 데이터 수집기술의 개념
- 빅데이터 수집 기술은 조직 내부와 외부의 분산된 여러 데이터 소스로부터 필요로 하는 데이터를 검색하여 수동 또는 자동으로 수집하는 과정과 관련된 기술
- 일반적으로 조직 내부에 존재하는 정형 데이터는 로그 수집기를 통해 수집하고, 조직 외부에 존재하는 비정형 데이터는 크롤링, RSS Reader, 또는 소셜 네트워크 서비스에서 제공하는 Open API를 이용한 프로그래밍을 통해 수집
나. 빅 데이터 수집 도구
|
도구 |
구성도 |
내용 |
|
Splunk (스플런크) |
|
- 프리 버전과 엔터프라이즈 버전을 제공 - 엔터프라이즈 버전에서는 하둡과 통합이 되어서 HDFS에 데이터를 저장하고 하둡에서 분석 프로세싱을 할 수 있도록 업그레이드됨 - 웹 기반의 GUI을 제공하고 있어서 그 사용성이나 관리적인 측면에서는 매우 큰 강점이 있음 |
|
Flume (플럼) |
|
- 에이전트, 컬렉터, 스토리지티어로 구분 - 데이터 수집을 위한 다양한 데이터 플로우 토폴로지를 구성할 수 있고 마스터 노드에서 통합 관리할 수 있는 웹페이지를 제공할 뿐만 아니라 이를 통해서 설정을 쉽게 변경하거나 모니터링이 가능 - 마스터 노드를 이중화하여 가용성이 높고, 자바로 구현되어 있어서 다양한 OS 플랫폼에 포팅이 가능함 |
|
Chukwa (척와) |
|
- 에이전트(Agent), 컬렉터(Collector), MapReduce 처리, HICC(Hadoop Infrastructure Care Center)로 구성됨 - 척와는 확장성이 뛰어나며 대용량의 처리가 가능 분산시스템으로 모니터링과 분석 기능 클러스터 환경의 로그 분석에 탁월함 - 오픈소스 기술 |
|
Scribe (스크라이브) |
- Facebook이 개발하여 2008년에 공개한 로그 수집 기술 - 대량의 서버로부터 실시간으로 흘러오는 로그 데이터를 집약하기 위해 개발됨 |
|



다. 빅 데이터 자동수집 방법
|
수집방법 |
설명 |
|
로그수집기 |
- 조직 내부에 존재하는 웹서버의 로그 수집, 웹 로드, 트랜잭션 로그, 클릭 로그, DB 로그 데이터 등을 수집 |
|
크롤링 |
- 주로 웹로봇을 이용하여 조직 외부에 존재하는 소셜 데이터 및 인터넷에 공개되어 있는 자료를 수집 |
|
센싱 |
- 각종 센서를 통해 데이터를 수집 |
|
RSS, Open API |
- 데이터의 생산, 공유, 참여 환경인 웹 2.0을 구현하는 기술로 필요한 데이터를 프로그래밍을 통해 수집 |
VI. 빅 데이터와 기존 기술의 비교
가. 빅 데이터와 기존 데이터(경영정보)의 차이점
|
구분 |
빅 데이터 |
기존 데이터 |
|
Volume |
- 수십 PB [페타바이트] |
- 수십 GB, TB |
|
Velocity |
- 실시간 처리 기반(Real Time) |
- 적합한 시간 내 처리 (Right Time) |
|
Variety |
- Legacy 데이터 및 트랜잭션 - 모바일, 소셜 데이터, 각종 로그 |
- 기업 내부 발생 데이터 위주 - ERP, CRM, SCM 등 Legacy 데이터 |
|
Device |
- On/Off Line 데이터 포함 - Transaction 및 로그 데이터포함 |
- On-line 데이터 기반 - Transaction Data 기반 |
나. 전통적 데이터와 빅 데이터의 비교
|
구분 |
전통적 데이터 |
빅 데이터 |
|
데이터 원천 |
- 전통적 정보 서비스 |
- 일상화된 정보 서비스 |
|
목적 |
- 업무, 효율성 |
- 사회적 소통, 자기표현, 사회기반 서비스 |
|
생성주체 |
- 정부, 기업 등 조직 |
- 개인, 시스템 등 |
|
데이터유형 |
- 정형 데이터 - 조직 내부 데이터(고객정보, 거래정보 둥) - 주로 비공개 데이터 |
- 비정형 데이터(비디오 스트림, 이미지, 오디오, 소셜 네트워크 등의 사용자 데이터, 센서 데이터, 응용프로그램 데이터 등) - 조직 외부 데이터 - 일부 공개 데이터 |
|
데이터 특징 |
- 데이터 증가량 관리 가능 - 신뢰성 높은 핵심 데이터 |
- 기하급수적 양적 증가 - Garbage 데이터 비중 높음 - 문맥정보 등 다양한 데이터 |
|
데이터 보유 |
- 정부, 기업 등 대부분 조직 |
- 인터넷 서비스 기업(구글, 아마존 등) - 포털(네이버, 다음 등) - 이동통신회사(SKT, KTF 등) - 디바이스생산회사(애플 삼성전자 등) |
|
데이터 플랫폼 |
- 정형 데이터를 생산, 저장, 분석, 처리할 수 있는 전통적 플랫폼 - ex) 분산 DBMS, 중앙집중처리multi-processor, |
- 비정형의 대량 데이터를 생산, 저장, 분석, 처리할 수 있는 새로운 플랫폼 - ex) 대용량 비정형 데이터 분산 병렬 처리 |
VII. 빅 데이터 활용을 위한 이슈 및 방안
|
구분 |
이슈 |
방안 |
|
Data 접근성 |
- 외부 제3자 Data 활용가능성 - 내/외부 Data의 체계적 결합 및 전사적 이용가능성 |
- 프라이버시, 보안, 지식재산권, 법적 책임 관련 사전 준비 - 외부 DB의 내부 활용 방안 |
|
Big Data 인프라 |
- 클라우드 기반 통합 분석 시스템 - 전사적 Data 통합 활용체계 |
- 분산된 Data의 클라우드 기반 통합 - Data 공유 프로세스 정립 |
|
분석역량 |
- 대용량 Data 분석 기술 - 실시간 분석, 시각화 등 |
- 내부 DB와의 결합 분석 - 실시간 의사결정 지원 방안 |
|
Data 중심 조직 |
- 전문적 분석 조직 및 전문인력 양성 - Data 기반 의사결정 조직 구조 |
- Big Data 분석 전문조직 검토 - 전문가 채용 |
'기타정보' 카테고리의 다른 글
| 빅데이터 분석기법, Random Forest의 개요 (0) | 2020.01.21 |
|---|---|
| 과잉 학습으로 인한 폐해, 과적합(Overfitting)의 개요 (0) | 2020.01.21 |
| 빅데이터 시각화 (0) | 2020.01.21 |
| 공공정보의 민간개방을 통한 선순환 생태계 조성, 오픈데이터(Open Data) 개요 (0) | 2020.01.21 |
| RFP(Request For Proposal) (0) | 2020.01.20 |